想要爬取一个论坛一篇帖子的评论区内容,都是精华,它的网页是鼠标向下滚动加载的,非常长,所以使用了 Web Scraper 来帮忙抓取。
插件的安装就不说了,网上教程挺多,直接说抓取内容。
首先 Create new sitemap,创建一个爬取器。
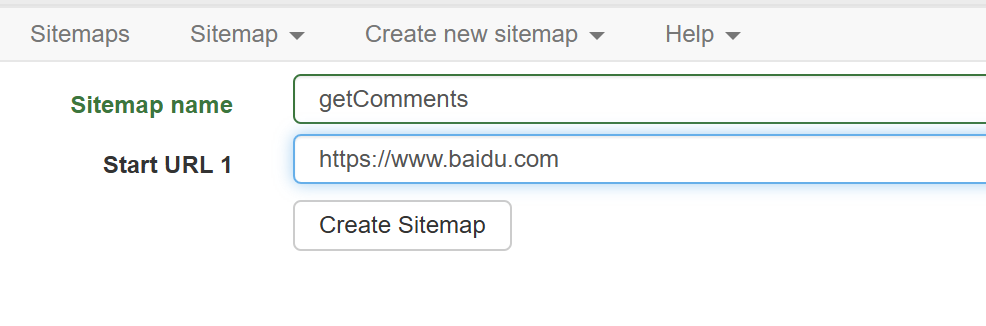
进入到网页,选中整个评论区,一定是整个评论区所在的父 Div。
之后 add new selector,ID 可以随便取,为了保证语义,取作 allComments。
这里需要说下,因为鼠标是需要一直向下滚动的,所以 Type 选择 Element(scroll),Multiple 要勾选。
最重要的是 Scroll 一定要勾选,后面的 Element limit 空着不填就可以,Element limit 用来限制 Web Scraper 对父选择器中匹配到的子元素的抓取数量。
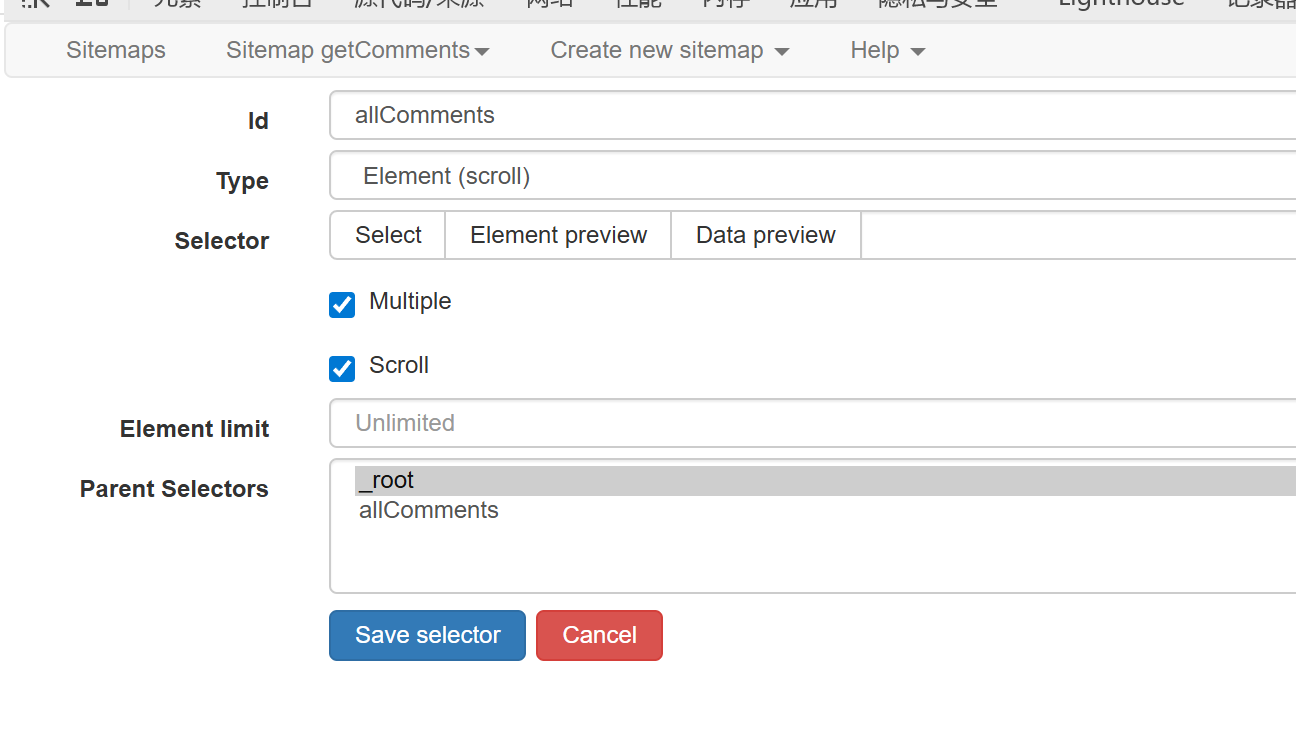

下图是选择评论区元素:
以上抓取器创建成功后并没有结束,这里只是指定了评论区,我们还需要指定你要抓取的评论区的字段,比如我只需要评论内容这一个内容,所以再创建一个子选择器去定义抓取字段(或区域)。这里需要特别注意的是 Multiple Type 的选择:
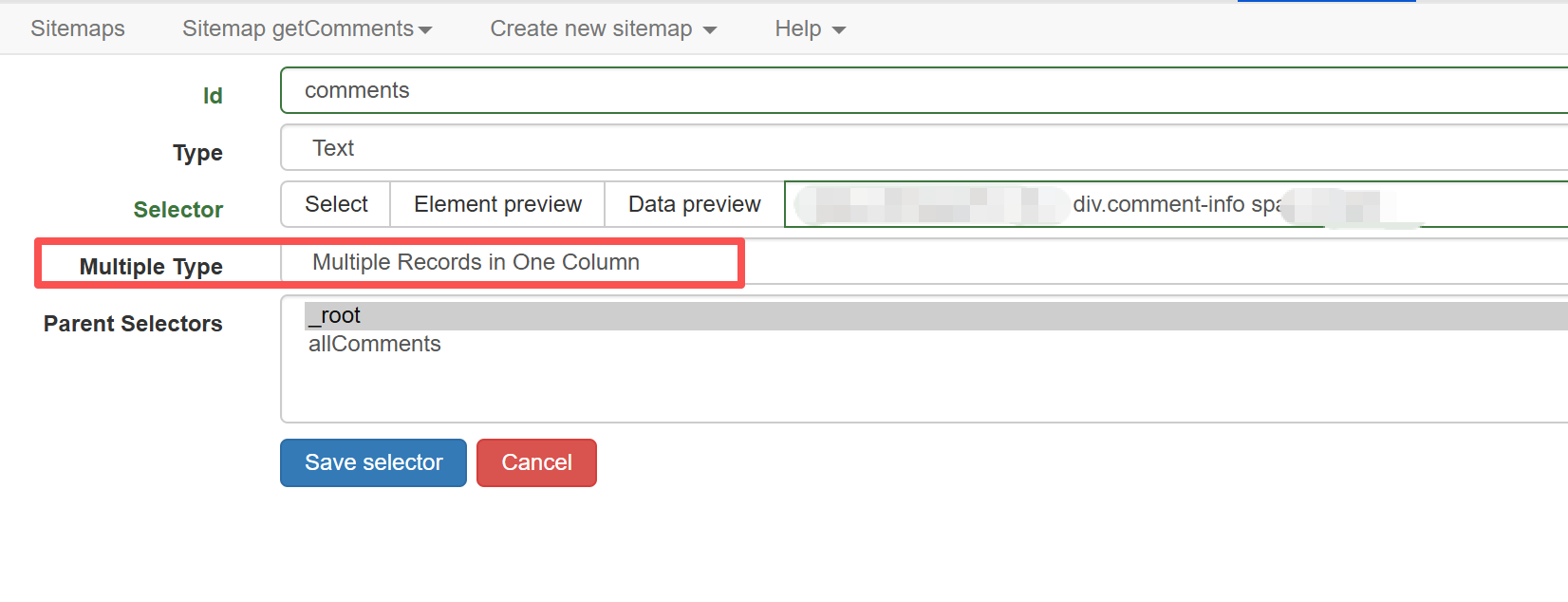

其他两个选项的意思和使用场景如下:


点击 save selector 保存。之后点击 Sitemap getComments(你的抓取器名称)之后选择 Scraper,就可以看到弹出一个新页面,去向下滑动抓取。
抓取完成后,抓取完成后,点击一下这里的 refresh,刷新之后能够看到数据,
点击下拉菜单中的 Export data 就可以导出 Excel 或者 Csv 文件。

这里需要给小白指明一点容易被误导的地方(我自己就被误导了),点 Scraper 去抓取的时候,页面弹出一下马上就关闭了,什么也没抓取到,提示 No data scraped yet,如下:

我以为是因为我要抓取的页面是需要登录的,而新弹出的网页没有登录,所以抓不到评论数据,然后还去查了很久怎么让弹出的网页能够是登录状态的。事实上纯粹就是因为我前面设置的不对,导致的没有抓取到数据,与是否登录无关的,如果前面设置正确了,弹出的页面本身就是登录状态的,是能够自动滚动抓取的。
以上就是我使用 Web Scraper 抓取数据的全过程,希望能够帮助到遇到同样问题的你。